Population model¶
The population model serves as an ancillary tool to distribute, disaggregate yearly population projections onto a geospatial representation. Occasionally, the output of this model is required as an independent variable for downstream models.
South Sudan¶
The population model used for South Sudan is grounded on a method called Component Analysis (or Component Method) 1, which takes into account Crude Birth Rates (CBR), Crude Death Rates (CDR), and migration rates (inmigration and outmigration). Any of these rates may change in a linear or non-linear fashion.
popt = popt-1 + popt-1 * CBRt*(1 + birth_rate_fct) - popt-1 * CDRt *(1 + death_rate_fct) + Immigrationt- Outmigrationt
In this equaiton, death/birth_rate fct is applied to the nominal growth rates. It is used for sensitivity studies of changes in the growth rate. For example, if one uses a birth_rate_fct of 0.1 this will boost the nominal growth rates by 10%. These variables are put in place to account for any possible bias in the census data.
Ethiopia¶
The dataset for Ethiopia have population projection values from UNFPA (United Nations Population Funds), and does not have growth rate values (birth, death rates).
The Data¶
In this model, all of the projected values are based on the last census conducted in South Sudan in 2008 before its independence from Sudan in 2011. The census was carried out by the Sudanese government, and there’s speculation that numbers for the regions within South Sudan were underestimated for political reason at the time.
For Ethiopia, the population projected values from UNFPA are available for 2000-2020.
Other data such as shapefiles for geospatial boundaries are also utilized for rasterizing the output. Here’s the list of raw data used for this model along with the source.
Data preprocessing¶
Raw data from difference sources were pooled together for the population projection values, and the adminstrative names have all been normalized by the Data collection team at Kimetrica.
Using the model¶
The population model is not a machine learning model. It works by distributing projected or census population values into adminstrative boundaries or high resolution raster (1km pixel resolution).
To generate the high resolution raster, the model leverages the LandScan population density raster which has density values calculated based on admin2 level. Using the density raster pixels, the given population value in a model run can be distributed spatially onto the map.
In order to run the population model for different countries, the user needs to specify input argument country-level,time, as well as geography. Other parameters refer to rain scenario and does not affect the this model but it’s nice to define them to make sure they are consistent with other models that runs on those parameters.
Outputs of the model¶
Currently, the .tiff and .geojson outputs contain population estimation for different demographic groups, please see population_model.yml for more information. If tabular format is required, then task EstimatePopulation can be used to return a .csv file, but it will not have the actual geospatial coordinates such as polygon objects.
The yearly projected population is at the county level (admin2) because all of the other models operate at the same administrative level. The output from this model can be rasterized into a .tiff file where it takes the population density raster from LandScan and distribute the admin2 population values to a 1km2 resolution. The task to run this is HiResPopRasterMasked.
An example output of RasterizedPopGeojson is shown below. It contains key-value pairs for the different demographic groups (see population_model.yml). Please note this format is quite large, and it is recommended to use the raster output from HiResPopRasterMasked instead (see Fig.1)
{"type": "Feature", "geometry": {"type": "Polygon", "coordinates": [[[38.672262668148974, 13.512720413943356], [38.672262668148974, 13.504386209150328], [38.68059472484714, 13.504386209150328], [38.68059472484714, 13.512720413943356], [38.672262668148974, 13.512720413943356]]]}, "properties": {"population_btotl": 1014196.0}}...
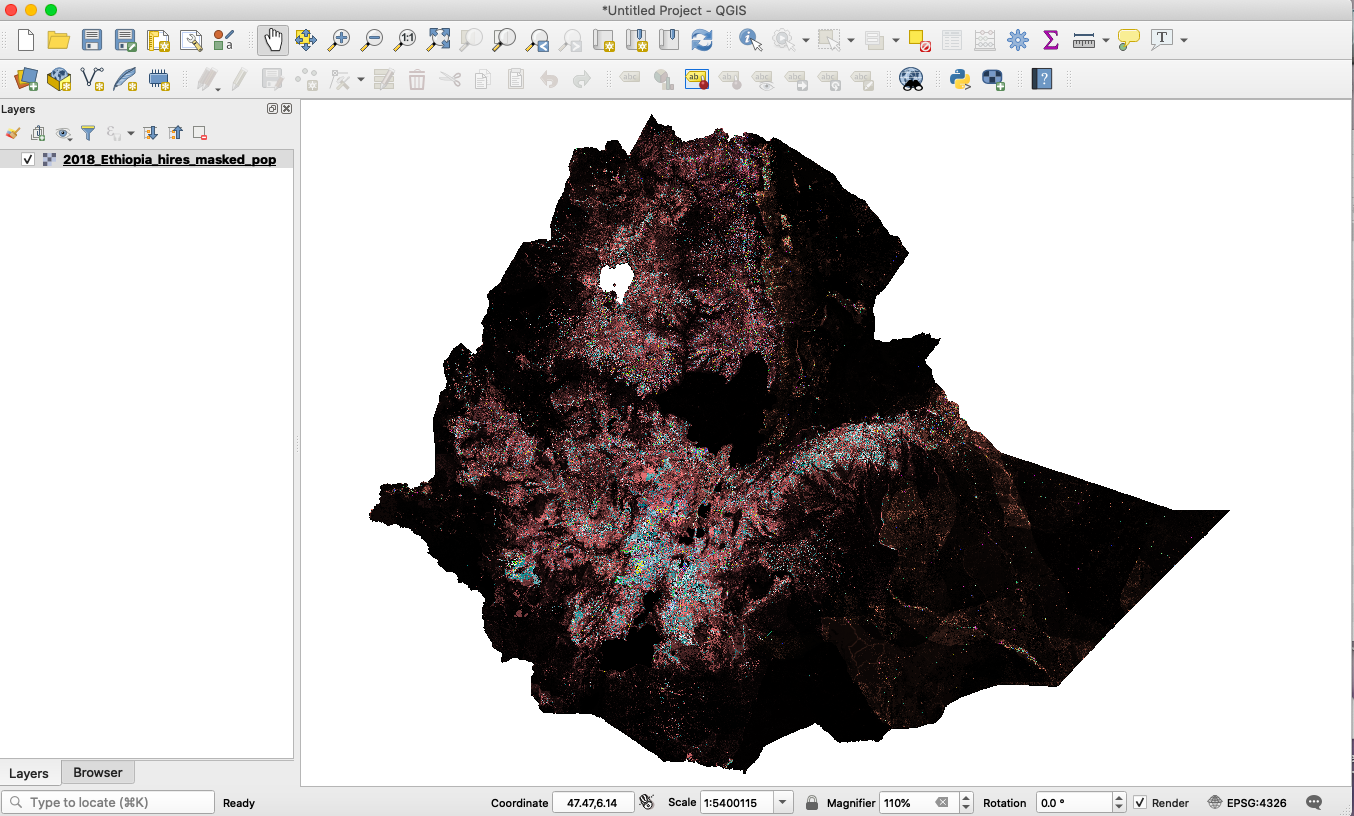
Fig.1. An example population raster for Ethiopia (displayed in QGIS). The raster consists of 23 bands total for the different demographic groups.
Quickstart code¶
To run the population for South Sudan 2018, the command line is
luigi --module models.population_model.tasks models.population_model.tasks.HiResPopRasterMasked \
--time 2018-04-01-2018-09-01 --local-scheduler
For Ethiopia, the command line is
luigi --module models.population_model.tasks models.population_model.tasks.HiResPopRasterMasked \
--time 2018-04-01-2018-09-01 --rainfall-scenario-time 2018-05-01-2018-05-10 --country-level Ethiopia --local-scheduler
In general, the rainfall-scenario-time should fall within the interval specified by time.
In addition to tiff format, geoJSON files can be generated from the hi-resolution raster by the task RasterizedPopGeojson. For South Sudan, an example command is:
luigi --module models.population_model.tasks models.population_model.tasks.RasterizedPopGeojson \
--time 2018-04-01-2018-09-01 --rainfall-scenario-time 2018-05-01-2018-05-10 --local-scheduler
And for Ethiopia, the command is
luigi --module models.population_model.tasks models.population_model.tasks.RasterizedPopGeojson \
--time 2018-04-01-2018-09-01 --rainfall-scenario-time 2018-05-01-2018-05-10 --country-level Ethiopia --local-scheduler
Constraints¶
The model currently supports output corresponding to admin2 and admin3 levels.
Population output values of South Sudan are available from 2008 onward; for Ethiopia the population projected values from UNFPA are available for 2000-2020.
Future work¶
The density raster file for Sudan is now available after Lisa Jordan had processed the raw LandScan raster data, and it can be found at this CKAN link.
Other density raster files are available for Ethiopia and South Sudan. These files are derived from the output of the building-detection model, and Lisa processed the outputs to normalize the pixels to population percentage values.